elasti
Introduction
Elasti is a Kubernetes-native solution that offers scale-to-zero functionality when there is no traffic and automatic scale up to 0 when traffic arrives. Most Kubernetes autoscaling solutions like HPA or Keda can scale from 1 to n replicas based on cpu utilization or memory usage. However, these solutions do not offer a way to scale to 0 when there is no traffic. Elasti solves this problem by dynamically managing service replicas based on real-time traffic conditions. It only handles scaling the application down to 0 replicas and scaling it back up to 1 replica when traffic is detected again. The scaling after 1 replica is handled by the autoscaler like HPA or Keda.
The name Elasti comes from a superhero “Elasti-Girl” from DC Comics. Her superpower is to expand or shrink her body at will—from hundreds of feet tall to mere inches in height.
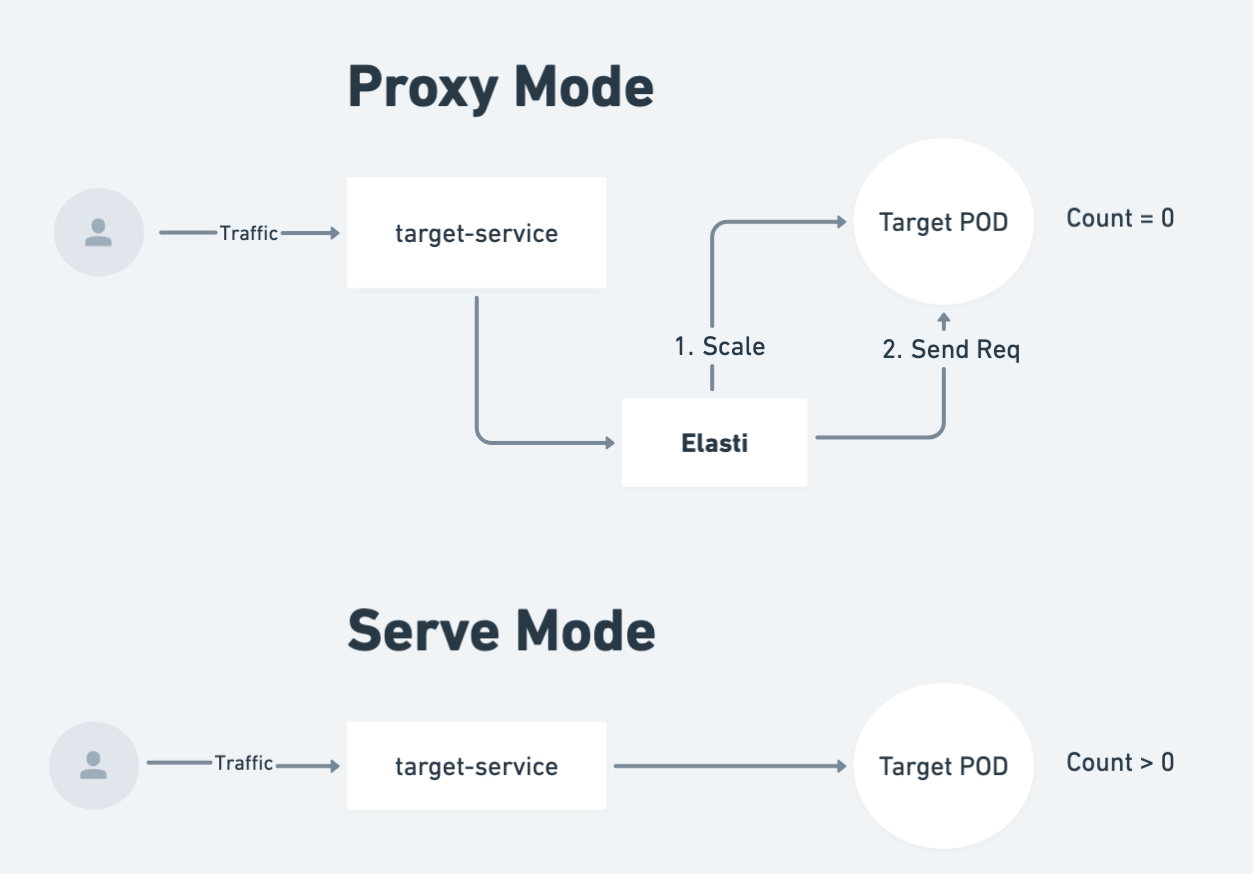
Elasti uses a proxy mechanism that queues and holds requests for scaled-down services, bringing them up only when needed. The proxy is used only when the service is scaled down to 0. When the service is scaled up to 1, the proxy is disabled and the requests are processed directly by the pods of the service.
How It Works
Elasti continuously monitors an ElastiService by evaluating a set of custom triggers defined in its configuration. These triggers represent various conditions—such as traffic metrics or other custom signals—that determine whether a service should be active or scaled down.
-
Scaling Down:
When all triggers indicate inactivity or low demand, Elasti scales the target service down to 0 replicas. During this period, elasti switches into proxy mode and queues incoming requests instead of dropping them. -
Traffic Queueing in Proxy Mode:
In Proxy Mode, Elasti intercepts and queues incoming requests directed at the scaled-down service. This ensures that no request is lost, even when the service is scaled down to 0. -
Scaling Up:
If any trigger signals a need for activity, Elasti immediately scales the service back up to its minimum replicas. As the service comes online, Elasti switches to Serve Mode. -
Serve Mode:
In Serve Mode, the active service handles all incoming traffic directly. Meanwhile, any queued requests accumulated during Proxy Mode are processed, ensuring a seamless return to full operational capacity.
This allows Elasti to optimize resource consumption by scaling services down when unneeded, while its request queueing mechanism preserves user interactions and guarantees prompt service availability when conditions change.
Key Features
-
Seamless Integration: Elasti integrates effortlessly with your existing Kubernetes setup - whether you are using HPA or Keda. It takes just a few steps to enable scale to zero for any service.
-
Deployment and Argo Rollouts Support: Elasti supports two scale target references: Deployment and Argo Rollouts, making it versatile for various deployment scenarios.
-
Prometheus Metrics Export: Elasti exports Prometheus metrics for easy out-of-the-box monitoring. You can also import a pre-built dashboard into Grafana for comprehensive visualization.
-
Generic Service Support: Elasti works at the kubernetes service level. It also supports East-West traffic using cluster-local service DNS, ensuring robust and flexible traffic management across your services. So any ingress or service mesh solution can be used with Elasti.
Limitations
- Only HTTP is supported: Elasti currently supports requests that are routed to the service via HTTP. In the future we will support more protocols like TCP, UDP etc.
- Only Deployment and Argo Rollouts are supported: Elasti supports two scale target references: Deployment and Argo Rollouts. In the future this will be made generic to support all target references that support the
/scalesubresource. - Prometheus Trigger: The only trigger currently supported is Prometheus
Please checkout the comparison here to see how Elasti compares to other Kubernetes autoscaling solutions.